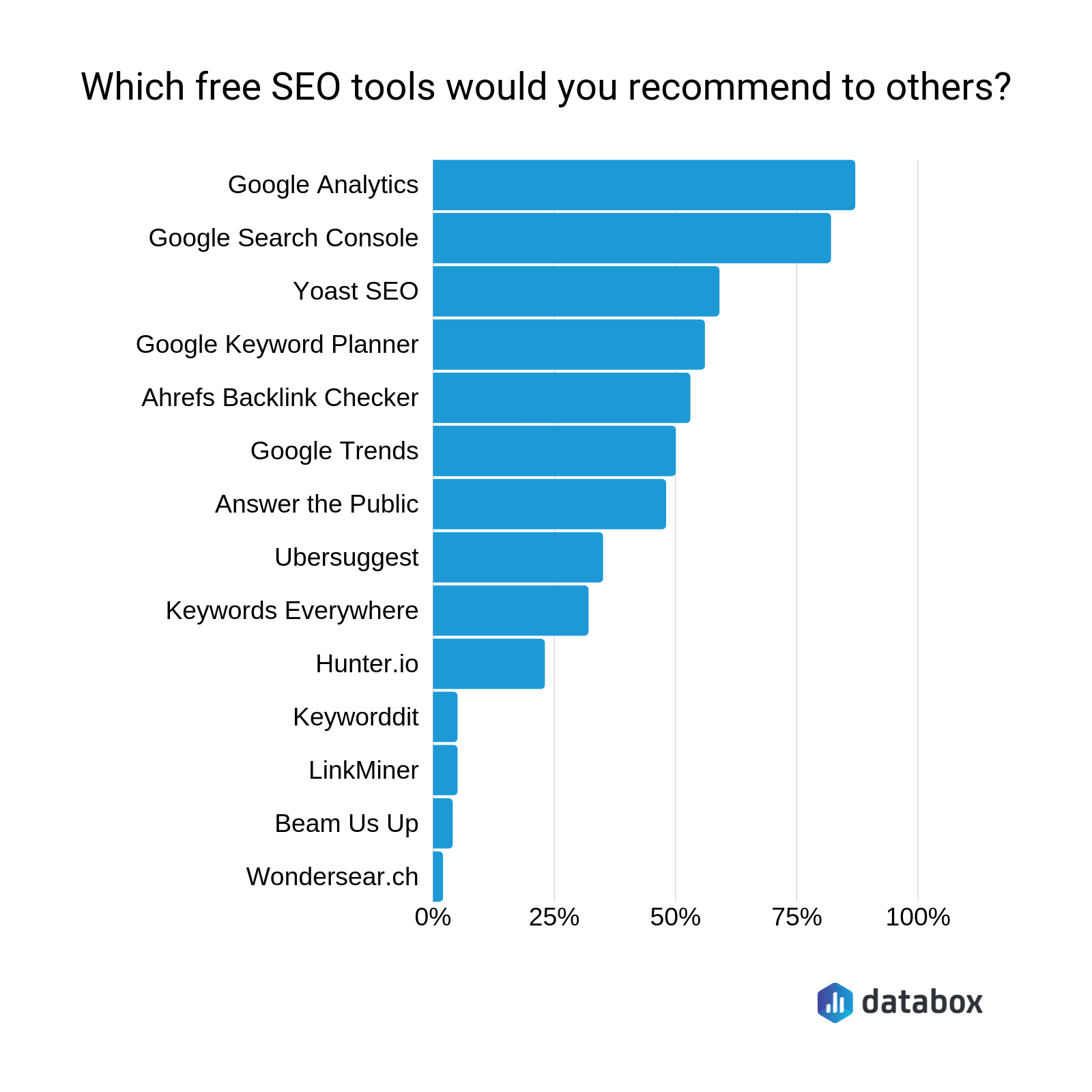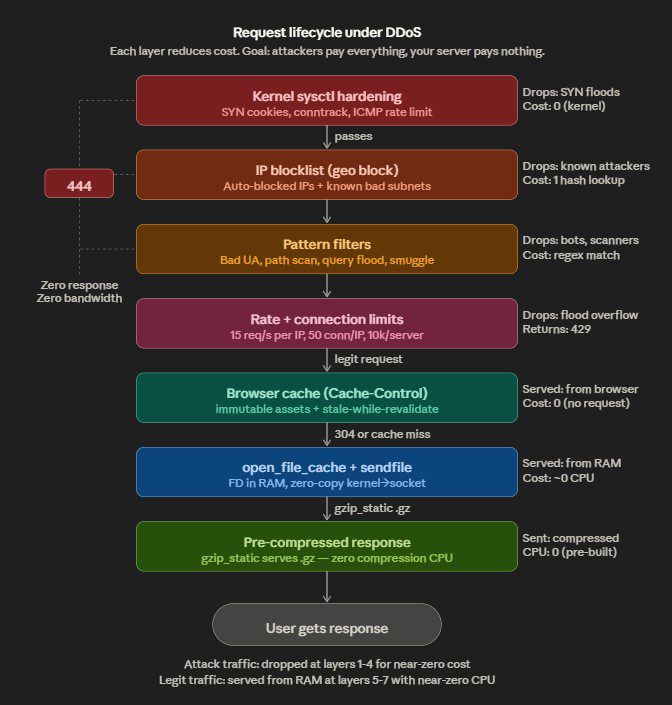
This is an Nginx-layer DDoS mitigation toolkit — two versions (v2 simple, v3 advanced) — designed to protect web servers running behind Nginx on Ubuntu without relying entirely on external services like Cloudflare.
Core purpose: Drop malicious traffic as early and as cheaply as possible — at the Nginx/kernel level — before it ever touches your application (PHP-FPM, Node, Python, etc.).
Nginx Anti DDOS Attack on Github
How it works, in layers:
The toolkit stacks defenses from kernel up to application layer. At the bottom, sysctl hardening handles SYN floods, conntrack exhaustion, and IP spoofing at the kernel before packets even reach Nginx. Then Nginx’s map directives pattern-match against known attack signatures — random query floods like /?abc=RANDOM, path scanners probing /.env or /wp-login.php, bad user-agents, referer spam, HTTP smuggling — and returns 444 (drop connection, zero response body, costs almost nothing). Rate limiting and connection limits cap per-IP request rates. A geo block drops traffic from known-bad IP ranges immediately.
The auto-blocker script is the adaptive piece — it runs on cron, tails the access log, detects IPs exhibiting attack patterns across five detection vectors (query floods, POST floods, path scanning, 4xx hammering, raw frequency), auto-aggregates them into /24 or /48 subnets when enough IPs cluster, and hot-reloads Nginx. v3 adds TTL-based expiry so the blocklist doesn’t grow forever, a whitelist with proper CIDR matching (v2’s was broken — exact string match only), size caps, and webhook/email alerting.
The cache hardening layer (v3 only) is the survivability play — open_file_cache keeps file descriptors in RAM, gzip_static serves pre-compressed files with zero CPU, micro-cache turns 10k DDoS requests/sec into 1 backend hit. The idea is that even traffic passing through the filters costs your server nearly nothing to serve.
What it does NOT do: This isn’t a WAF, it doesn’t do deep packet inspection, it won’t stop application-layer logic attacks, and it can’t handle volumetric attacks that saturate your pipe before reaching Nginx. For that you still need upstream filtering (Cloudflare, AWS Shield, etc.). This toolkit handles what gets through to your box.
v2 vs v3: v2 is a minimal drop-in — one pattern match, one blocklist, one cron job. v3 is the production version with five detection patterns, kernel hardening, cache hardening, IPv6 support, TTL purge, alerting, proper CIDR whitelisting, logrotate, and an install/uninstall script.
2GB RAM (I assume you mean RAM, not VRAM) with ~16 domains is tight but survivable — if you tune aggressively. Without tuning, you’ll OOM under any real load.
Here’s the problem. The v3 toolkit defaults are designed for beefy servers:
nf_conntrack_max = 1,000,000 eats ~256MB alone. The open_file_cache max=50000 plus four limit_req_zone and two limit_conn_zone totaling 70MB of shared memory zones, plus proxy_cache at 1GB max — that’s already exceeding your total RAM before Nginx even serves a request.
What you need to change for 2GB:
For the sysctl config, drop nf_conntrack_max to 128000 (~32MB). For the Nginx ddos-global.conf, cut the zone sizes — ddos_req_limit:5m, ddos_auth_limit:2m, ddos_post_limit:2m, ddos_download_limit:2m, ddos_conn_limit:5m, ddos_server_conn:2m. For cache-global.conf, reduce open_file_cache max=5000, and cut proxy_cache_path max_size to 128m or skip proxy cache entirely if your sites are static. Kill the tmpfs cache mount idea completely — you can’t spare 512MB of RAM. Set MAX_BLOCKLIST_ENTRIES to 10000 instead of 50000.
Worst case: Under a real DDoS, conntrack fills, Nginx worker memory spikes from 16 server blocks, the OOM killer nukes Nginx or your database, and everything goes down.
Best case with tuning: Static sites on 2GB with 16 vhosts is fine — Nginx is extremely efficient. Each idle server block costs almost nothing. The real question is what’s behind those domains — if it’s all static HTML, you’re good. If you’re running PHP-FPM, MySQL, Node, or any backend, 2GB is already a problem without the DDoS toolkit.