Google Search Console Errors List
If Google’s crawler, Googlebot, encounters an issue when it tries to crawl your site and doesn’t understand a page on your website, it’s going to give up and move on. This means your page will not be indexed and will not be visible to searchers, which greatly affects your search performance.
Here are some of those errors:
- Server Error (5xx)
- Redirect Error
- Blocked by robots.txt
- Marked ‘noindex’
- Soft 404
- Unauthorized request (401)
- Not Found (404)
- Crawl Issue
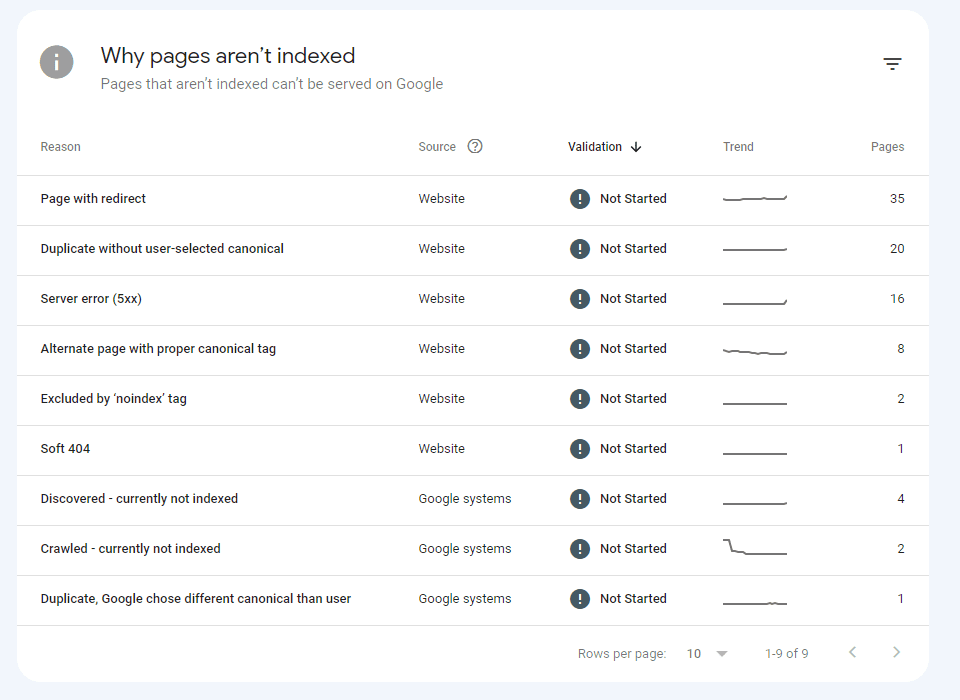
Crawled – currently not indexed:
The page was crawled by Google, but not indexed. It may or may not be indexed in the future; no need to resubmit this URL for crawling.
If you see this, take a good hard look at your content. Does it answer the searcher’s query? Is the content accurate? Are you offering a good experience for your users? Are you linking to reputable sources? Is anyone else linking to it?
Make sure to provide a detailed framework of all the page content that needs to be indexed through the use of structured data. This allows search engines to not only index your content but for it to come up in future queries and possible featured snippets.
Optimizing the page may increase the chances that Google chooses to index it the next time it is crawled.
Discovered – currently not indexed:
The page was found by Google, but not crawled yet.
Even though Google discovered the URL it did not feel it was important enough to spend time crawling. If you want this page to receive organic search traffic, consider linking to it more from within your own website. Be sure to promote this content to others with the hope that you can earn backlinks from external websites. External links to your content is a signal to Google that a page is valuable and considered to be trustworthy, which increases the odds of it being indexed.
Alternate page with proper canonical tag:
This page is a duplicate of a page that Google recognizes as canonical, and it correctly points to that canonical page, so nothing for you to do here!
Just as the tool says, there’s really nothing to do here. If it bothers you that the same page is accessible through more than one URL, see if there is a way to consolidate.
Duplicate without user-selected canonical::
This page has duplicates, none of which is marked canonical. We think this page is not the canonical one. You should explicitly mark the canonical for this page.
Google is guessing which page you want them to index. Don’t make it guess. You can explicitly tell Google which version of a page should be indexed using a canonical tag.
Duplicate non-HTML page:
A non-HTML page (for example, a PDF file) is a duplicate of another page that Google has marked as canonical.
Google discovered a PDF on your site that contained the same information as a normal HTML page, so they chose to only index the HTML version. Generally, this is what you want to happen, so no action should be necessary unless for some reason you prefer they use the PDF version instead.
Duplicate, Google chose different canonical than user:
This URL is marked as canonical for a set of pages, but Google thinks another URL makes a better canonical.
Google disagrees with you on which version of a page they should be indexing. The best thing you can do is make sure that you have canonical tags on all duplicate pages, that those canonicals are consistent, and that you’re only linking to your canonical internally. Try to avoid sending mixed signals.
We’ve seen this happen when a website specifies one version of a page as the canonical, but then redirects the user to a different version. Since Google cannot access the version you have specified, it assumes perhaps that you’ve made an error, and overrides your directive.
Soft 404:
The page request returns what we think is a soft 404 response.
In Google’s eyes, these pages are a shell of their former selves. The remnants of something useful that once existed, but no longer does. You should convert these into 404 pages, or start populating them with useful content.
Submitted URL dropped:
You submitted this page for indexing, but it was dropped from the index for an unspecified reason.
This issue ‘s description is pretty vague, so it’s hard to say with certainty what action you should take. Our best guess is that Google looked at your content, tried it out for a while, then decided to no longer include it.
Investigate the page and critique its overall quality. Is the page thin? Outdated? Inaccurate? Slow to load? Has it been neglected for years? Have your competitors put out something that’s infinitely better?
Try refreshing and improving the content, and secure a few new links to the page. It may lead to a re-indexation of the page.
Duplicate, Submitted URL not selected as canonical:
The URL is one of a set of duplicate URLs without an explicitly marked canonical page. You explicitly asked this URL to be indexed, but because it is a duplicate, and Google thinks that another URL is a better candidate for canonical, Google did not index this URL. Instead, we indexed the canonical that we selected.
Viewport not set
The page does not define a viewport property, which tells browsers how to adjust the page’s dimension and scaling to suit the screen size. Because visitors to your site use a variety of devices with varying screen sizes—from large desktop monitors, to tablets and small smartphones—your pages should specify a viewport using the meta viewport tag.
The “viewport” is the technical way that your browser knows how to properly scale images and other elements of your website so that it looks great on all devices. Unless your HTML savvy, this will likely require the help of a developer. If you want to take a stab at it, this guide might be helpful.
Viewport not set to “device-width”
The page defines a fixed-width viewport property, which means that it can’t adjust for different screen sizes. To fix this error, adopt a responsive design for your site’s pages, and set the viewport to match the device’s width and scale accordingly.
In the early days of responsive-design, some developers preferred to tweak the website for mobile-experiences rather than making the website fully responsive. The fixed-width viewport is a great way to do this, but as more and more mobile devices enter the market, this solution is less appealing.
Google now favors responsive web experiences. If you’re seeing this issue, it’s likely that you’re frustrating some of your mobile users, and potentially losing out on some organic traffic. It may be time to call an agency or hire a developer to make your website responsive.
Content wider than screen
Horizontal scrolling is necessary to see words and images on the pageThis happens when pages use absolute values in CSS declarations, or use images designed to look best at a specific browser width (such as 980px). To fix this error, make sure the pages use relative width and position values for CSS elements, and make sure images can scale as well.
This usually occurs when there is a single image or element on your page that isn’t sizing correctly for mobile devices. In WordPress, this can commonly occur when an image is given a caption or a plug-in is used to generate an element that isn’t native to your theme.
The easy way to fix this issue is to simply remove the image or element that is not sizing correctly on mobile devices. The correct way to fix it is to modify your code to make the element responsive.
Text too small to read
The font size for the page is too small to be legible and would require mobile visitors to “pinch to zoom” in order to read. After specifying a viewport for your web pages, set your font sizes to scale properly within the viewport.
Simply put, your website is too hard to read on mobile devices. To experience this first-hand, simply load the page in question on a smartphone and experience it first hand.
According to Google, a good rule of thumb is to have the page display no more than 70 to 80 characters (about 8-10 words) per line on a mobile device. If you’re seeing more than this, you should hire an agency or developer to modify your code.
How To Fix A Server error (5xx):
Your server returned a 500-level error when the page was requested.
A 500 error means that something has gone wrong with a website’s server that prevented it from fulfilling your request. In this case, something with your server prevented Google from loading the page.
First, check the page in your browser and see if you’re able to load it. If you can, there’s a good chance the issue has resolved itself, but you’ll want to confirm.
Email your IT team or hosting company and ask if the server has experienced any outages in recent days, or if there’s a configuration that might be blocking Googlebot and other crawlers from accessing the site.
How To Fix A Redirect error:
The URL was a redirect error. Could be one of the following types: it was a redirect chain that was too long; it was a redirect loop; the redirect URL eventually exceeded the max URL length; there was a bad or empty URL in the redirect chain.
This basically means your redirect doesn’t work. Go fix it!
A common scenario is that your primary URL has changed a few times, so there are redirects that redirect to redirects. Example: http://yourdomain.com redirects to http://www.yourdomain.com which then redirects to https://www.yourdomain.com.
Google has to crawl a ton of content, so it doesn’t like wasting time and effort crawling these types of links. Solve this by ensuring your redirect goes directly to the final URL, eliminating all steps in the middle.
Submitted URL blocked by robots.txt:
You submitted this page for indexing, but the page is blocked by robots.txt. Try testing your page using the robots.txt tester.
There is a line of code in your robots.txt file that tells Google it’s not allowed to crawl this page, even though you’ve asked Google to do just that by submitting it to be indexed. If you do actually want it to be indexed, find and remove the line from your robots.txt file.
If you don’t, check your sitemap.xml file to see if the URL in question is listed there. If it is, remove it. Sometimes WordPress plugins will sneak pages into your sitemap file that don’t belong.
Submitted URL marked ‘noindex’:
You submitted this page for indexing, but the page has a ‘noindex’ directive either in a meta tag or HTTP response. If you want this page to be indexed, you must remove the tag or HTTP response.
Submitted URL seems to be a Soft 404:
You submitted this page for indexing, but the server returned what seems to be a soft 404.
These are pages that look like they are broken to Google, but aren’t properly showing a 404 Not Found response. These tend to bubble up in two ways:
- You have a category page with no content within that category. It’s like an empty shelf at a grocery store.
- Your website’s theme is automatically creating pages that shouldn’t exist.
You should either convert these pages to proper 404 pages, redirect them to their new location, or populate them with some real content.
For more on this issue, be sure to read our in-depth guide to fixing Soft 404 errors.
Submitted URL returns unauthorized request (401):
You submitted this page for indexing, but Google got a 401 (not authorized) response. Either remove authorization requirements for this page, or else allow Googlebot to access your pages by verifying its identity.
This warning is usually triggered when Google attempts to crawl a page that is only accessible to a logged-in user. You don’t want Google wasting resources attempting to crawl these URLs, so you should try to find the location on your website where Google discovered the link, and remove it.
For this to be “submitted”, it would need to be included in your sitemap, so check there first.
Submitted URL not found (404):
You submitted a non-existent URL for indexing.
If you remove a page from your website but forget to remove it from your sitemap, you’re likely to see this error. This can be prevented from regular maintenance of your sitemap file.
Deep Dive Guide: For a closer look at how to fix this error, read our article about how to fix 404 errors on your website.
Submitted URL has crawl issue:
You submitted this page for indexing, and Google encountered an unspecified crawling error that doesn’t fall into any of the other reasons. Try debugging your page using the URL Inspection tool.
Indexed, though blocked by robots.txt:
The page was indexed, despite being blocked by robots.txt
Your robots.txt file is sort of like a traffic cop for search engines. It allows some crawlers to go through your site and blocks others. You can block crawlers at the domain level or on a page by page basis.
Unfortunately, this specific warning is something we see all the time. It usually happens when someone attempts to block a bad bot and puts in an overly strict rule.
Below is an example of a local music venue that we noticed was blocking all crawlers from accessing the site, including Google. Don’t worry, we let them know about it.
Submitted and indexed:
You submitted the URL for indexing, and it was indexed.
You wanted the page indexed, so you told Google about it, and they totally dug it. You got what you wanted, so go pour yourself a glass of champagne and celebrate!
Indexed, not submitted in sitemap:
The URL was discovered by Google and indexed.
Google found these pages and decided to index them, but you didn’t make it as easy as you could have. Google and other search engines prefer that you tell them about the content you want to have indexed by including them in a sitemap. Doing so can potentially increase the frequency in which Google crawls your content, which may translate into higher rankings and more traffic.
Indexed; consider marking as canonical:
The URL was indexed. Because it has duplicate URLs, we recommend explicitly marking this URL as canonical.
A duplicate URL is an example of a page that is accessible through multiple variations even though it is the same page. Common examples include when a page is accessible both with and without a backslash, or with a file extension at the end. Something like yoursite.com/index.html and yoursite.com, which both lead to the same page.
These are bad for SEO because it dilutes any authority a page accumulates through external backlinks between the two versions. It also forces a search engine to waste its resources crawling multiple URLs for a single page and can make your analytics reporting pretty messy as well.
A canonical tag is a single line in your HTML that tells search engines which version of the URL they should prioritize, and consolidates all link signals to that version. They can be extremely beneficial to have and should be considered.
Google Search Console Excluded URLs
These are the pages that Google discovered, but chose to not index. For the most part, these will be pages that you explicitly told Google not to index. Others are pages that you might actually want to have indexed, but Google chose to ignore them because they weren’t found to be valuable enough.