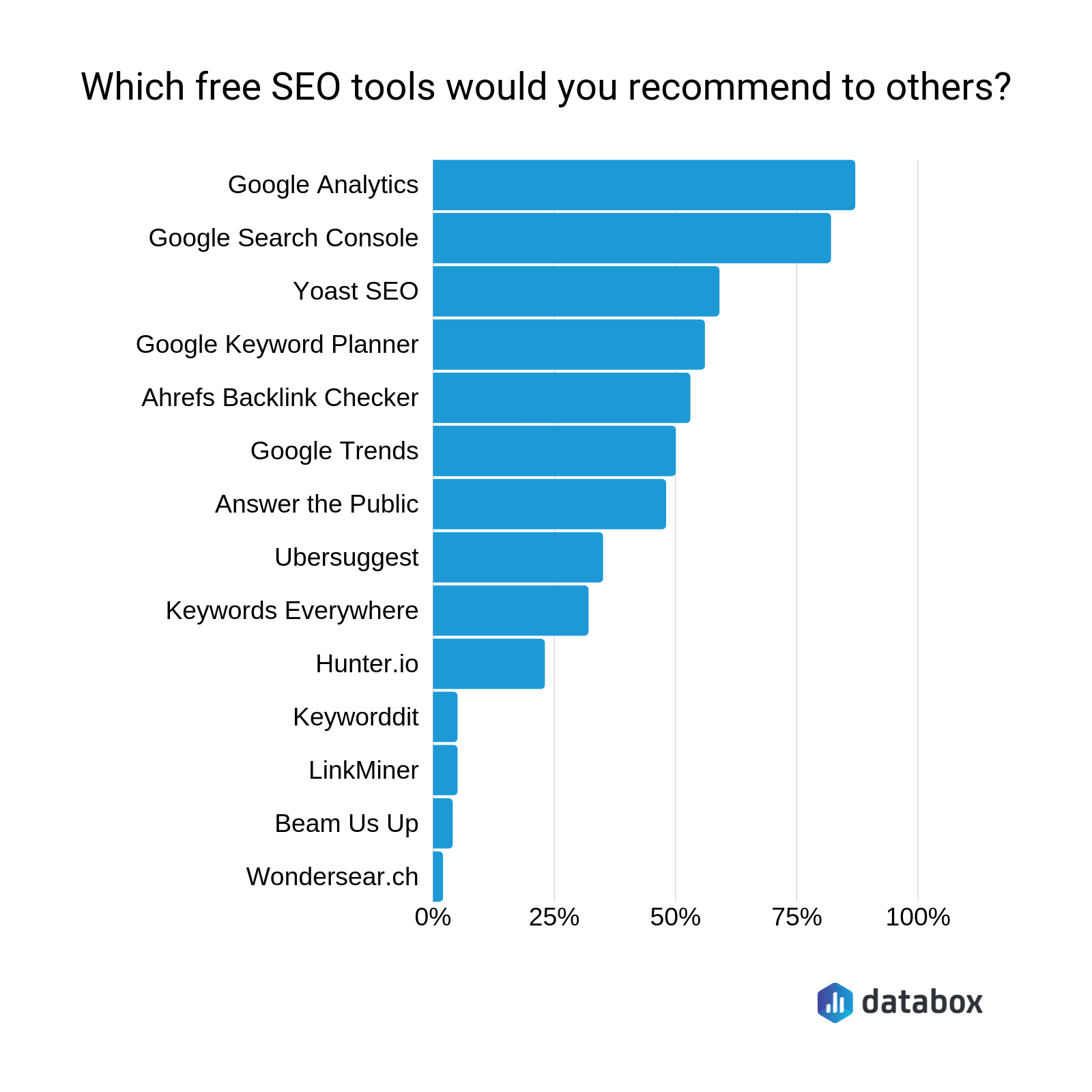
Scan your website & get a roadmap for SEO strategy, backlinks, UX, semantics & content. A free list of tailored improvements for your website. Get it in 4 minutes! 32+ trillion backlinks. Analyze your on-page SEO in one click, get customized suggestions and improve your. rankings. Audit your site today to improve engagement for your audiences!
Link Building is King. Harness that Social Media Power. Add an RSS Feed Subscription Box. Don’t Shy from Blog Commenting. Guest Posting is Still Hot. Forums Posting Is a Thing. Build Trust.
On-page SEO focuses on optimizing parts of your website that are within your control, while off–page SEO focuses on increasing the authority of your domain. Try to use my domain to check the metric https://josuamarcelc.com you may compare it with yours.
In the world of Search Engine Optimization (SEO), understanding the behavior of search engine crawlers is crucial. These crawlers, also known as bots or spiders, are automated programs used by search engines like Google, Bing, and others to scan and index the content of websites. By identifying the IP ranges of these crawlers, webmasters can optimize their websites more effectively. This article delves into the top crawlers, their IP ranges, and how this knowledge benefits SEO.
Crawlers are automated programs that visit websites to read and index their content. They follow links from one page to another, thereby creating a map of the web that search engines use to provide relevant search results.
Importance in SEO
Recognizing crawlers is essential in SEO as it ensures that your website is indexed correctly. Proper indexing increases the chances of your website appearing in search results, thereby driving organic traffic.
Top Search Engine Crawlers and Their IP Ranges
Googlebot
Primary Role: Indexing websites for Google Search.
IP Range: Googlebot IPs typically fall within the range owned by Google. However, due to the vast number of IP addresses Google owns, it’s more efficient to verify Googlebot by using the reverse DNS lookup method.
Bingbot
Primary Role: Crawling for Microsoft’s Bing search engine.
IP Range: Bingbot also uses a range of IP addresses. Similar to Googlebot, it’s advisable to use reverse DNS lookups to confirm the legitimacy of Bingbot.
Baiduspider
Primary Role: Indexing for the Baidu search engine, predominantly used in China.
IP Range: Baiduspider’s IP ranges are published by Baidu and can be found in their webmaster tools documentation.
Yandex Bot
Primary Role: Crawling for Russia’s Yandex search engine.
IP Range: Yandex provides a list of IP addresses for its crawlers, which can be found in their official documentation.
Why Knowing IP Ranges Matters
Security: Distinguishing between legitimate crawlers and malicious bots is crucial for website security.
Accurate Analytics: Identifying crawler traffic helps in obtaining more accurate analytics data, as it separates human traffic from bot traffic.
SEO Optimization: Understanding crawler behavior helps in optimizing websites for better indexing and ranking.
Resource Management: It helps in managing server resources effectively, as crawlers can consume significant bandwidth.
Best Practices for Managing Crawler Traffic
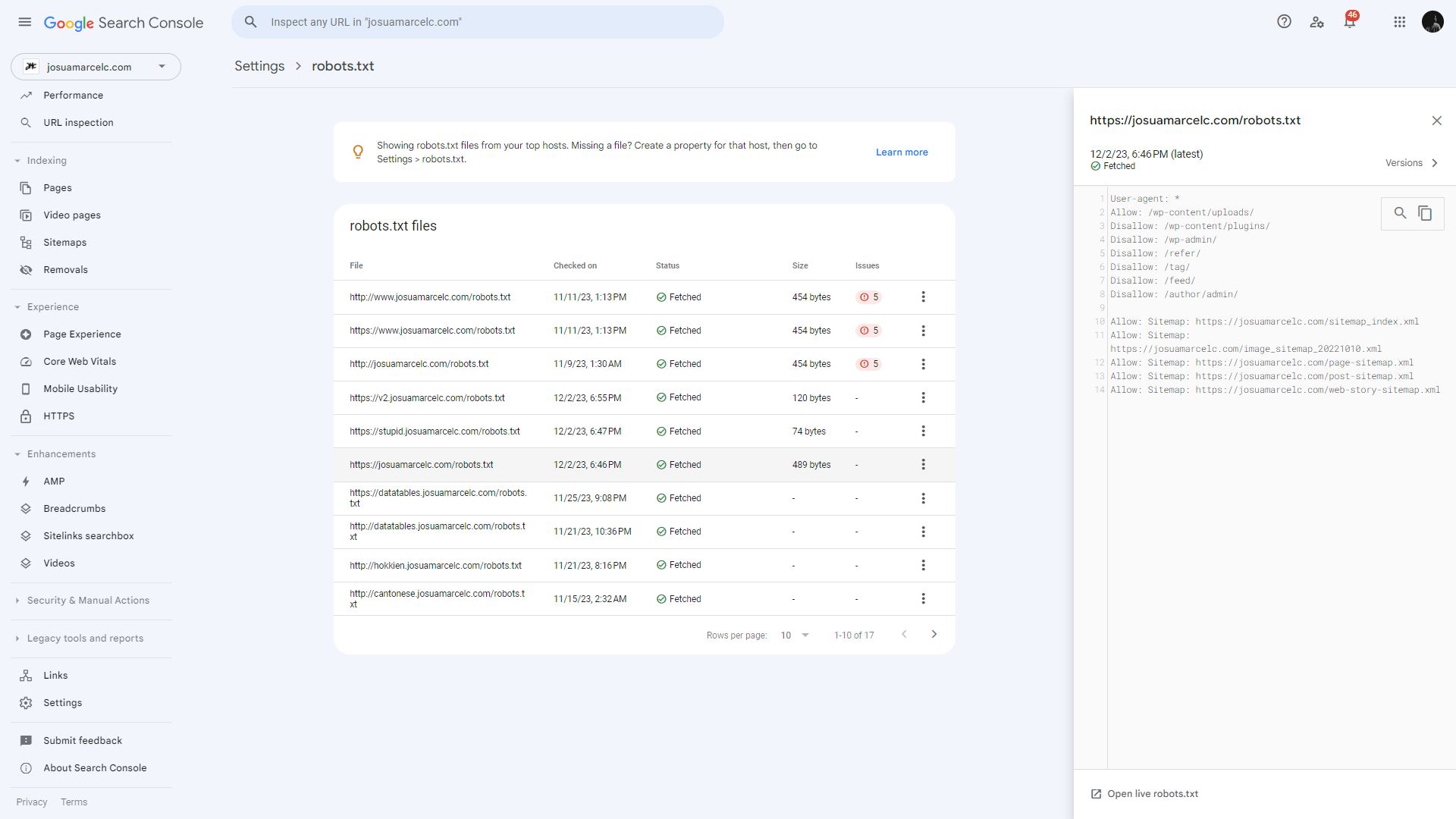
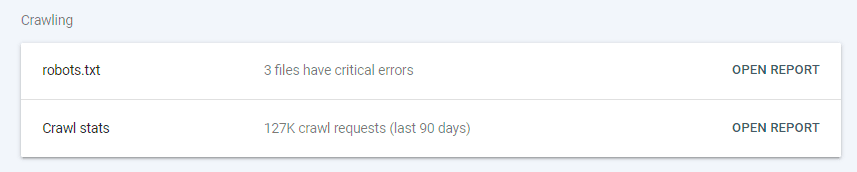
Robots.txt File: Use this to guide crawlers on which parts of your site to scan and which to ignore.
Monitoring Server Logs: Regularly check server logs for crawler activities to ensure that your site is being indexed properly.
Updating Sitemaps: Keep your sitemaps updated to aid crawlers in efficient website navigation.
Conclusion
Recognizing and understanding the IP ranges of top search engine crawlers is a vital aspect of SEO. It helps in distinguishing between genuine search engine bots and potential security threats, enhances website performance, and contributes to more effective SEO strategies. As search engines evolve, staying informed about crawler activities and best practices is essential for maintaining and improving your website’s search engine visibility.
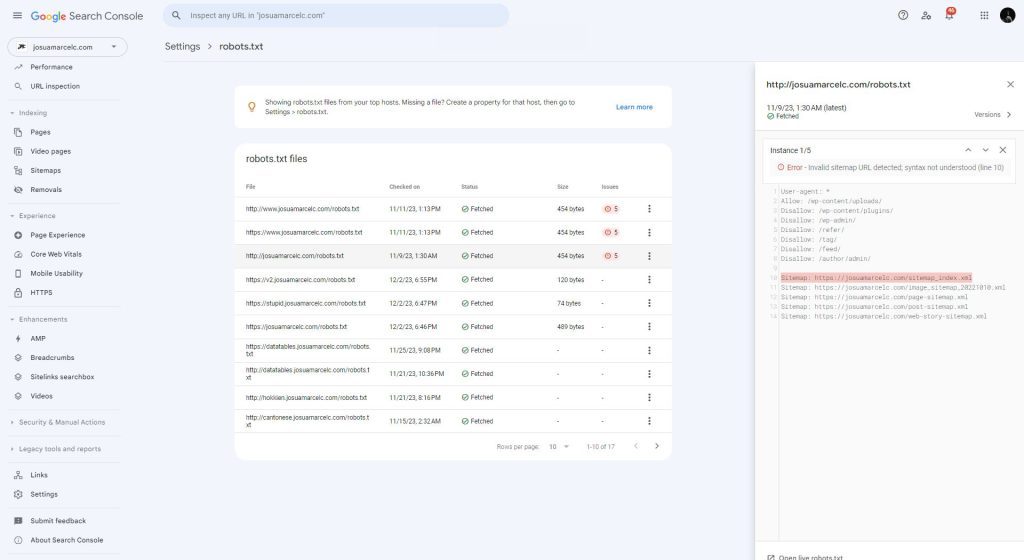
Allow: sitemap: [Optional, zero or more per file] The location of a sitemap for this site. The sitemap URL must be a fully-qualified URL; Google doesn’t assume or check http/https/www.non-www alternates. Sitemaps are a good way to indicate which content Google should crawl, as opposed to which content it can or cannot crawl.
Submitting your sitemap to search engines via HTTP can be done using a straightforward method. Here are the general steps to submit your sitemap using an HTTP request:
Create or Generate Your Sitemap:
If you haven’t already, create a valid XML sitemap for your website. This sitemap should list all the URLs you want search engines to index.
Host the Sitemap on Your Web Server:
Upload your sitemap file to your web server or hosting account. You should be able to access it via a URL, such as https://yourwebsite.com/sitemap.xml.
Use a Web Browser or Command-Line Tool:
You can use a web browser or a command-line tool like curl or wget to send an HTTP request to search engines. Below are examples of how to do this:
Using a Web Browser:
Open your web browser and visit the respective URL to submit your sitemap to Google or Bing:
For Google: https://www.google.com/ping?sitemap=https://yourwebsite.com/sitemap.xmlFor Bing: https://www.bing.com/ping?sitemap=https://yourwebsite.com/sitemap.xml
Replace https://yourwebsite.com/sitemap.xml with the actual URL of your sitemap.
Using Command-Line Tools (e.g., curl):
Open your command-line interface and run one of the following commands to submit your sitemap to Google:bashCopy codecurl -H "Content-Type: text/plain" --data "https://yourwebsite.com/sitemap.xml" "https://www.google.com/ping?sitemap"
Or submit your sitemap to Bing:bashCopy codecurl -H "Content-Type: text/plain" --data "https://yourwebsite.com/sitemap.xml" "https://www.bing.com/ping?sitemap"
Check the Response:
After submitting the HTTP request, you should receive a response from the search engine. This response will typically indicate whether the sitemap submission was successful.
Monitor Search Console:
Although submitting via HTTP can notify search engines of your sitemap, it’s a good practice to monitor your Google Search Console and Bing Webmaster Tools accounts. These tools provide more insights into the indexing status of your website and any potential issues.
Submitting your sitemap via HTTP is a convenient and straightforward way to inform search engines about your website’s structure and content updates. However, keep in mind that while this method helps with initial discovery, it does not replace the need for regular monitoring and management of your website’s SEO through official search engine webmaster tools.
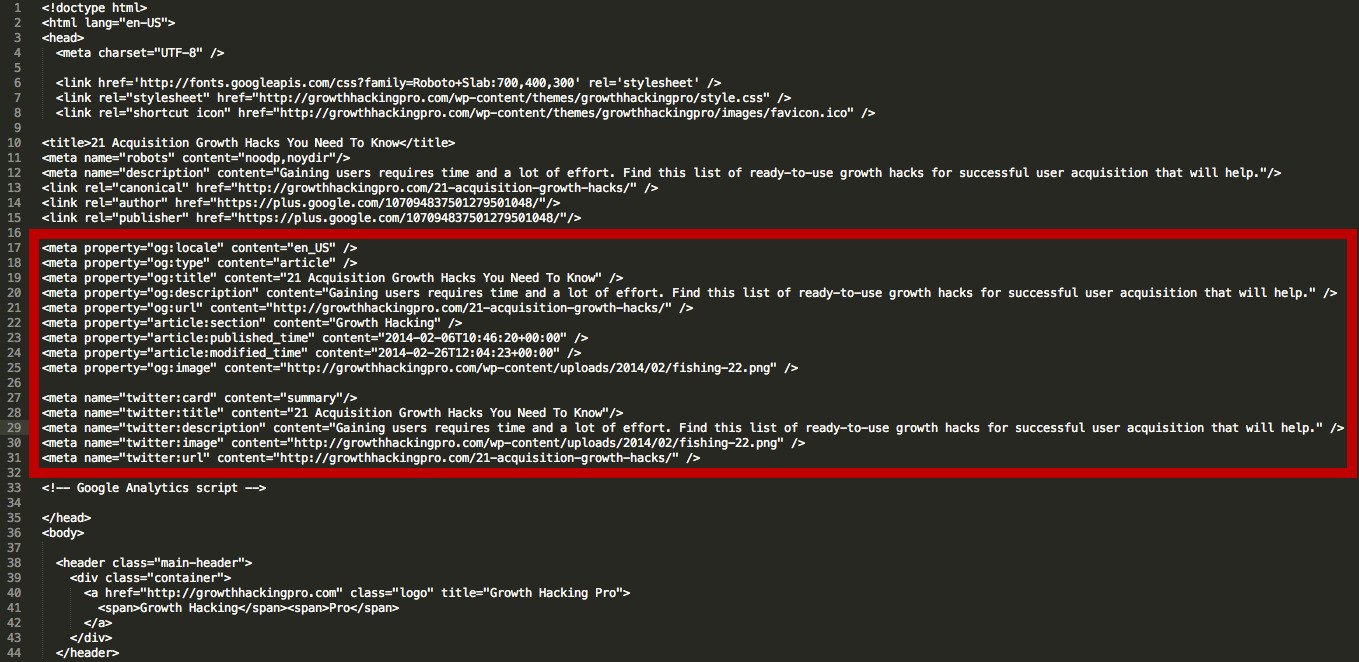
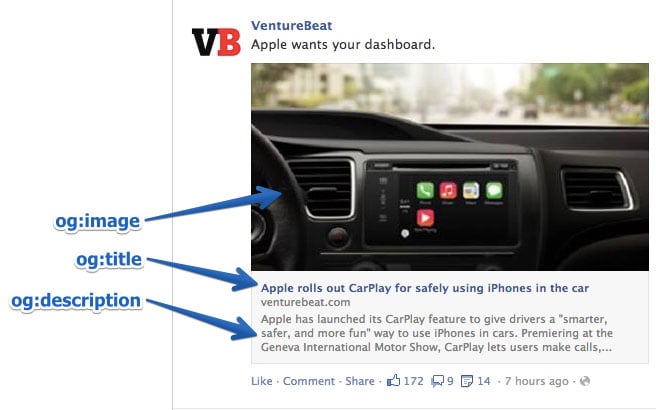
og:title – This is the title of your webpage. Remember that this will be shown whenever someone links your website, so make it quick, snappy and able to draw attention.
og:site_name – The name of your website. Remember that this differs from the actual title of your webpage and is usually shown under the title itself.
og:description – A brief description of your website. This should be no more than 2 sentences. Make sure it’s to the point and able to attract clicks.
og:type – This is a tag to determine the type of content. A full list of types can be found at https://developers.facebook.com/docs/reference/opengraph/. The type you use will change the way the content is displayed. For instance, using the “music.song” type will represent a single song and open up additional tags such as music:album which represents the album and music:release_date which is when the song was released.
og:image – URL for an image that you want to display. The minimum size is 50 by 50 pixels and must be in JPEG, GIF or PNG formats.
og:url – The URL that you want your content to link to.
These are the most important tags to keep in mind. Remember that if you use a specific type such as music.song, you’ll need to add extra tags to fill in more information. Here is another Open Graph reference resource with a full list of all the types and their associated tags.
Open Graph Tag Integration The simplest way to integrate Open Graph tags is to add them to thecontainer of your page’s HTML files. This might sound complicated for regular web users, but there’s also an easier way if you use WordPress or another website builder.
For example, there’s an official Facebook plugin that can be attached to your website, but eCommerce modules such as Zen Cart and Shopify also support Open Graph integration. Yoast SEO is our favorite choice and makes setting Open Graph meta tags a breeze. However, if you know your way around HTML and don’t have many pages to set up and want to keep it simple, then you can simply add them to the HTML files of your webpage.
Just replace the property and content in quotes with your relevant tags, and add as many as you need.
Some platforms use their own social media tags. For instance, Twitter uses Twitter Cards which work in a similar fashion. However, if Twitter doesn’t detect any Twitter Card tags, it will default to Open Graph. This makes Open Graph a universally accepted protocol that generally works with every website, hence why it’s such an important tool to utilize.
If you don’t use Open Graph, then you’re seriously harming your chances of getting more exposure. When people do actually share your website, you want people to see what your website is about, some relevant information and an accurate image. By neglecting Open Graph tags, you could potentially be losing a lot of business.
If you’re a web design agency then your clients absolutely expect this. If you need help setting up open graph or additional technical SEO requirements schedule a free consultation with us and we’ll get you on the right path.